import gzip
import glob
import pickle
import numpy as np
from rdkit import Chem
from rdkit import rdBase
import rdkit
print(rdkit.__version__)
import matplotlib.pyplot as plt
%matplotlib inline
plt.style.use('tableau-colorblind10')2025.03.3[Post revised on 24.06.2025 to fix a mistake in the calculation of the FeatureMorgan fingerprints. Thanks to Kjell Jorner for pointing it out.]
This post is an exploration of the impact of molecule size on similarity thresholds for some of the fingerprints the RDKit supports. This is inspired by a question Kjell Jorner asked me earlier this week: “Are you aware of any studies (or blog posts) looking at the effect of molecular size on fingerprint similarity?”. I’m sure there are sources out there looking at this, but the question fits so well into my ongoing series of posts about similarity that I decided to just go ahead and do the analysis.
This post looks at the similarities between random molecules as a function of molecule size. I use a few of the fingerprints available in the RDKit. Along the way there’s also some info about the increase in the numbers of bits set in fingerprints as a function of molecule size.
It’s not as easy to summarize things here as it was when I looked at similarity thresholds in general, so there’s no big table here. The TLDR is that similarities (and thus thresholds) tend to increase with molecular size across all of the fingerprints. There may also be a small increase in the standard deviations of the similarity distributions as the molecules get larger, but since the distributions aren’t always gaussian (particularly for tranche 10), this is a weak signal.
It would also be interesting to try and look at the size dependence of the thresholds for related compounds, but there it’s going to be a bit trickier to divide the results into reasonable tranches.
import gzip
import glob
import pickle
import numpy as np
from rdkit import Chem
from rdkit import rdBase
import rdkit
print(rdkit.__version__)
import matplotlib.pyplot as plt
%matplotlib inline
plt.style.use('tableau-colorblind10')2025.03.3I use the number of heavy atoms as a surrogate for molecule size and collect five different tranches: - 10: 1-9 heavy atoms - 20: 10-19 heavy atoms - 30: 20-29 heavy atoms - 40: 30-39 heavy atoms - 50: 40-49 heavy atoms
This is the code used to collect tranches which each contain at least 10K molecules from PubChem Compound.
import random
fns = list(glob.glob('/fileserver/pine/pine1/glandrum/pubchem/Compound/Compound_*.sdf.gz'))
random.seed(0xa100f)
random.shuffle(fns)
accum = {10:[],20:[],30:[],40:[],50:[]}
def done(accum,tgt=2000):
for k,v in accum.items():
if len(v)<tgt:
return False
return True
bl = rdBase.BlockLogs()
for fn in fns[:10]:
print(fn)
with gzip.open(fn,'rb') as inf:
suppl = Chem.ForwardSDMolSupplier(inf,sanitize=False,removeHs=True)
taccum = {10:[],20:[],30:[],40:[],50:[]}
for i,mol in enumerate(suppl):
if not mol:
continue
if len(Chem.GetMolFrags(mol))>1:
continue
nAts = mol.GetNumHeavyAtoms()
for k in accum:
if nAts<k:
taccum[k].append(mol)
break
if not (i+1)%1000 and done(taccum):
break
for k in taccum:
# take at most 5K/tranche/file
accum[k].extend(taccum[k][:5000])
print([len(v) for v in accum.values()])
bl = None
with gzip.open('./results/pubchem_tranches.pkl.gz','wb+') as outf:
pickle.dump(accum,outf)with gzip.open('./results/pubchem_tranches.pkl.gz','rb') as inf:
accum = pickle.load(inf)print([len(v) for v in accum.values()])[10502, 50000, 50000, 31458, 28082]from rdkit.Chem import Draw
Draw.MolsToGridImage(accum[20][:10])
Those have Hs on them, so we’ll need to be sure to call RemoveHs() below.
Collect similarity values for bit-based and count-based fingerprints using
import random
from rdkit.Chem import rdFingerprintGenerator
from rdkit import DataStructs
from collections import defaultdict
fpgs = {'mfp0':rdFingerprintGenerator.GetMorganGenerator(radius=0),
'mfp1':rdFingerprintGenerator.GetMorganGenerator(radius=1),
'mfp2':rdFingerprintGenerator.GetMorganGenerator(radius=2),
'mfp3':rdFingerprintGenerator.GetMorganGenerator(radius=3),
'ffp0':rdFingerprintGenerator.GetMorganGenerator(radius=0,
atomInvariantsGenerator=rdFingerprintGenerator.GetMorganFeatureAtomInvGen()),
'ffp1':rdFingerprintGenerator.GetMorganGenerator(radius=1,
atomInvariantsGenerator=rdFingerprintGenerator.GetMorganFeatureAtomInvGen()),
'ffp2':rdFingerprintGenerator.GetMorganGenerator(radius=2,
atomInvariantsGenerator=rdFingerprintGenerator.GetMorganFeatureAtomInvGen()),
'ffp3':rdFingerprintGenerator.GetMorganGenerator(radius=3,
atomInvariantsGenerator=rdFingerprintGenerator.GetMorganFeatureAtomInvGen()),
'rdk5':rdFingerprintGenerator.GetRDKitFPGenerator(maxPath=5),
'rdk7':rdFingerprintGenerator.GetRDKitFPGenerator(maxPath=7),
'ap':rdFingerprintGenerator.GetAtomPairGenerator(),
'tt':rdFingerprintGenerator.GetTopologicalTorsionGenerator(),
}
bl = rdBase.BlockLogs()
sims_accum = defaultdict(dict)
csims_accum = defaultdict(dict)
bitcounts_accum = defaultdict(dict)
cbitcounts_accum = defaultdict(dict)
for k in accum:
print(f'Doing {k}')
fps = defaultdict(list)
cfps = defaultdict(list)
nMols = 0
print('\t generating fps')
for m in accum[k][:20000]:
try:
m = Chem.RemoveHs(m)
except:
continue
nMols += 1
for nm,fpg in fpgs.items():
fp = fpg.GetFingerprint(m)
fps[nm].append(fp)
cfp = fpg.GetSparseCountFingerprint(m)
cfps[nm].append(cfp)
random.seed(0xf00d)
indices = list(range(nMols))
indices2 = indices[:]
pairs = []
while len(pairs)<50000:
random.shuffle(indices)
random.shuffle(indices2)
pairs.extend(zip(indices,indices2))
pairs = pairs[:50000]
print('\t calculating similarities')
for fpn in fps:
bitcounts_accum[fpn][k] = [x.GetNumOnBits() for x in fps[fpn]]
cbitcounts_accum[fpn][k] = [len(x.GetNonzeroElements()) for x in cfps[fpn]]
sims_accum[fpn][k] = [DataStructs.TanimotoSimilarity(fps[fpn][x],fps[fpn][y]) for x,y in pairs if x!=y]
csims_accum[fpn][k] = [DataStructs.TanimotoSimilarity(cfps[fpn][x],cfps[fpn][y]) for x,y in pairs if x!=y]
Doing 10
generating fps
calculating similarities
Doing 20
generating fps
calculating similarities
Doing 30
generating fps
calculating similarities
Doing 40
generating fps
calculating similarities
Doing 50
generating fps
calculating similaritieswith gzip.open('./results/pubchem_tranches_accum.pkl.gz','wb+') as outf:
pickle.dump((sims_accum,csims_accum,bitcounts_accum,cbitcounts_accum),outf)Let’s start by looking at the quantile values for the various molecule sizes.
for fpn in sims_accum:
print(f'----- {fpn}')
for k in sims_accum[fpn]:
qs = np.quantile(sims_accum[fpn][k],(.7,.8,.9,.95,.99))
print(k,qs)----- mfp0
10 [0.2 0.25 0.33333333 0.4 0.55555556]
20 [0.36363636 0.41666667 0.5 0.54545455 0.66666667]
30 [0.41666667 0.46153846 0.53846154 0.6 0.72727273]
40 [0.5 0.53333333 0.6 0.66666667 0.76923077]
50 [0.52631579 0.5625 0.625 0.6875 0.78571429]
----- mfp1
10 [0.08333333 0.11111111 0.15 0.1875 0.26666667]
20 [0.16216216 0.18604651 0.22222222 0.25806452 0.35294118]
30 [0.1875 0.21212121 0.25 0.29411765 0.40912587]
40 [0.21212121 0.23333333 0.26666667 0.3 0.4 ]
50 [0.21126761 0.23188406 0.265625 0.3 0.45767458]
----- mfp2
10 [0.06060606 0.08 0.10810811 0.13333333 0.19230769]
20 [0.10769231 0.12307692 0.14705882 0.16949153 0.24137931]
30 [0.12 0.13513514 0.16049383 0.18666667 0.26229508]
40 [0.13274336 0.14583333 0.16666667 0.18811881 0.26436782]
50 [0.1328125 0.14634146 0.16806723 0.192 0.32352941]
----- mfp3
10 [0.05555556 0.07142857 0.09756098 0.12121212 0.17391304]
20 [0.08695652 0.09859155 0.11666667 0.13414634 0.1884058 ]
30 [0.09433962 0.10526316 0.12380952 0.14285714 0.19753086]
40 [0.1038961 0.11333333 0.12804878 0.14383562 0.19627336]
50 [0.10497238 0.11458333 0.13068182 0.1474359 0.25 ]
----- ffp0
10 [0.5 0.6 0.66666667 0.8 1. ]
20 [0.5 0.6 0.66666667 0.8 1. ]
30 [0.6 0.66666667 0.75 0.83333333 1. ]
40 [0.66666667 0.71428571 0.8 0.83333333 1. ]
50 [0.66666667 0.66666667 0.8 0.83333333 1. ]
----- ffp1
10 [0.21052632 0.25 0.33333333 0.38461538 0.54545455]
20 [0.25 0.29166667 0.34615385 0.4 0.52173913]
30 [0.28571429 0.32142857 0.375 0.43478261 0.57894737]
40 [0.31428571 0.34375 0.39393939 0.44 0.56 ]
50 [0.31707317 0.35 0.39534884 0.44444444 0.6 ]
----- ffp2
10 [0.13333333 0.16 0.2 0.23809524 0.33333333]
20 [0.1509434 0.17307692 0.20754717 0.24137931 0.32432432]
30 [0.16981132 0.19117647 0.22641509 0.26086957 0.36171313]
40 [0.17741935 0.19642857 0.22535211 0.25396825 0.34782609]
50 [0.17647059 0.19444444 0.22352941 0.25301205 0.40230165]
----- ffp3
10 [0.11764706 0.13888889 0.17647059 0.21052632 0.3 ]
20 [0.11267606 0.12820513 0.15151515 0.17460317 0.23728814]
30 [0.12087912 0.13541667 0.15957447 0.18333333 0.25287772]
40 [0.125 0.13709677 0.15602837 0.17592593 0.24175824]
50 [0.12318841 0.13496933 0.15483871 0.17432259 0.2920354 ]
----- rdk5
10 [0.07027027 0.09210526 0.13194444 0.1744186 0.29371452]
20 [0.138981 0.16265382 0.2034783 0.2464887 0.36241717]
30 [0.17901151 0.20031056 0.23529412 0.27119341 0.37744418]
40 [0.22476447 0.24408015 0.27403333 0.30361222 0.39875415]
50 [0.25178929 0.27223912 0.30226963 0.33179724 0.56276264]
----- rdk7
10 [0.06182973 0.07692308 0.10318025 0.13125631 0.20755116]
20 [0.16833891 0.18709195 0.21530125 0.24113382 0.3134873 ]
30 [0.26654377 0.29183192 0.33148058 0.36885969 0.44672696]
40 [0.40810447 0.441927 0.48827846 0.52855104 0.60776592]
50 [0.50135796 0.54613734 0.6083984 0.66037441 0.7468516 ]
----- ap
10 [0.05769231 0.078125 0.1147541 0.15 0.23809524]
20 [0.17808219 0.20089286 0.234375 0.26415094 0.33495146]
30 [0.25822785 0.28092784 0.31441048 0.34351535 0.40506573]
40 [0.34891018 0.3678844 0.39450643 0.41703057 0.46559644]
50 [0.40221239 0.42302158 0.44985673 0.47313237 0.53501519]
----- tt
10 [0. 0. 0.04166667 0.0625 0.15789474]
20 [0.06 0.08064516 0.11764706 0.15384615 0.23404255]
30 [0.11111111 0.13432836 0.17073171 0.2037037 0.28888889]
40 [0.14285714 0.1640625 0.1965812 0.22826087 0.32397031]
50 [0.15625 0.17763158 0.21186441 0.24603175 0.43928085]for fpn in csims_accum:
print(f'----- {fpn}')
for k in csims_accum[fpn]:
qs = np.quantile(csims_accum[fpn][k],(.7,.8,.9,.95,.99))
print(k,qs)----- mfp0
10 [0.14285714 0.2 0.28571429 0.33333333 0.45454545]
20 [0.31818182 0.36 0.42307692 0.47826087 0.59090909]
30 [0.4 0.44117647 0.5 0.54545455 0.65625 ]
40 [0.46666667 0.50980392 0.55813953 0.6 0.69047619]
50 [0.47368421 0.51724138 0.57142857 0.61818182 0.72340426]
----- mfp1
10 [0.06666667 0.09677419 0.13333333 0.17700535 0.27272727]
20 [0.17647059 0.20634921 0.24528302 0.28301887 0.37254902]
30 [0.23595506 0.26760563 0.31147541 0.35064935 0.44615385]
40 [0.28 0.30769231 0.34736842 0.38461538 0.47368421]
50 [0.29230769 0.32258065 0.36363636 0.40322581 0.51851852]
----- mfp2
10 [0.05263158 0.07317073 0.1025641 0.13157895 0.19444444]
20 [0.12195122 0.14117647 0.17045455 0.19753086 0.27058824]
30 [0.16129032 0.18181818 0.21282506 0.24137931 0.31461298]
40 [0.18987342 0.20886076 0.2384106 0.26712329 0.34210526]
50 [0.2 0.22105263 0.25252525 0.28249816 0.3908046 ]
----- mfp3
10 [0.04878049 0.06666667 0.09375 0.11904762 0.17647059]
20 [0.09803922 0.11304348 0.13541667 0.15740741 0.21649485]
30 [0.12658228 0.14184397 0.16546763 0.18791946 0.24648177]
40 [0.14680203 0.16129032 0.18378378 0.20621793 0.26530612]
50 [0.15471698 0.17063492 0.19465649 0.21825397 0.31429032]
----- ffp0
10 [0.54545455 0.6 0.7 0.77777778 0.88888889]
20 [0.54545455 0.60869565 0.68421053 0.75 0.85 ]
30 [0.5862069 0.63333333 0.7 0.75 0.85185185]
40 [0.65853659 0.7027027 0.75609756 0.79487179 0.86486486]
50 [0.67307692 0.72 0.7755102 0.8125 0.88372093]
----- ffp1
10 [0.28 0.33333333 0.39130435 0.44444444 0.56521739]
20 [0.33333333 0.37037037 0.42857143 0.47826087 0.57894737]
30 [0.38235294 0.42028986 0.47368421 0.51724138 0.62068966]
40 [0.44 0.47252747 0.51724138 0.55555556 0.64444444]
50 [0.45454545 0.49122807 0.53846154 0.57798165 0.66666667]
----- ffp2
10 [0.2 0.23076923 0.27777778 0.32 0.41176471]
20 [0.22857143 0.25641026 0.29850746 0.33766234 0.41666667]
30 [0.26666667 0.29411765 0.33333333 0.37234043 0.45796708]
40 [0.3028169 0.32692308 0.36464824 0.3968254 0.48150041]
50 [0.3172043 0.34444444 0.38323353 0.41758242 0.51875 ]
----- ffp3
10 [0.18181818 0.20930233 0.25 0.28571429 0.36842105]
20 [0.18095238 0.20212766 0.23469388 0.26436782 0.33333333]
30 [0.20588235 0.22683213 0.25735294 0.28703704 0.35652174]
40 [0.23036649 0.24870466 0.27717391 0.3025641 0.37291299]
50 [0.24180328 0.26199907 0.29147982 0.31836735 0.41262136]
----- rdk5
10 [0.05263158 0.078125 0.12244898 0.16853933 0.28378378]
20 [0.10666667 0.14024707 0.18987342 0.23607923 0.34835067]
30 [0.1451939 0.17281374 0.21733278 0.2604754 0.37288632]
40 [0.15921514 0.18334971 0.22246696 0.26200001 0.37742537]
50 [0.16637721 0.19188259 0.23143559 0.27172211 0.48031332]
----- rdk7
10 [0.04 0.05882353 0.09090909 0.12538641 0.20652354]
20 [0.04666459 0.06532277 0.09769524 0.13118911 0.22522836]
30 [0.06412657 0.08135525 0.11198197 0.14370902 0.23953108]
40 [0.06824623 0.08322877 0.1102338 0.13858556 0.24425887]
50 [0.07035962 0.08588146 0.11248808 0.14160011 0.38672073]
----- ap
10 [0.03225806 0.05 0.08888889 0.12280702 0.2 ]
20 [0.11934156 0.14218009 0.17624521 0.20866142 0.28304308]
30 [0.16820988 0.19254658 0.23012552 0.26355844 0.33653916]
40 [0.21548117 0.23770492 0.26982097 0.29846583 0.36480247]
50 [0.23087622 0.25611413 0.2919198 0.32415421 0.41593843]
----- tt
10 [0. 0. 0. 0. 0.08333333]
20 [0.03571429 0.05660377 0.09803922 0.13477131 0.2195122 ]
30 [0.0862069 0.11111111 0.14772727 0.18333333 0.26666667]
40 [0.11290323 0.13533835 0.17037037 0.2038835 0.2970297 ]
50 [0.12169312 0.14457831 0.18014589 0.21568627 0.40002817]Calculate means and std devs. Note that some of these distributions, particularly those for tranche 10, are not even remotely gaussian, so these values shouldn’t be taken overly seriously
print('bit-based')
print(f' fp \t 10 20 30 40 50')
for fpn in sims_accum:
means = [np.mean(vs) for vs in sims_accum[fpn].values()]
stds = [np.std(vs) for vs in sims_accum[fpn].values()]
blocks = [f'{x:.2f}({y:.2f})' for x,y in zip(means,stds)]
print(f'{fpn:4s} \t{" ".join(blocks)}')
# for k in sims_accum[fpn]:
# vs = sims_accum[fpn][k]
# print(f'{k}:\t{np.mean(vs):.2f}({np.std(vs):.2f})')bit-based
fp 10 20 30 40 50
mfp0 0.14(0.13) 0.30(0.14) 0.36(0.13) 0.43(0.13) 0.44(0.15)
mfp1 0.06(0.06) 0.13(0.07) 0.16(0.07) 0.19(0.07) 0.19(0.08)
mfp2 0.05(0.05) 0.09(0.05) 0.11(0.05) 0.12(0.05) 0.12(0.05)
mfp3 0.04(0.04) 0.07(0.04) 0.08(0.04) 0.09(0.03) 0.09(0.04)
ffp0 0.41(0.22) 0.45(0.18) 0.52(0.17) 0.57(0.17) 0.56(0.17)
ffp1 0.17(0.11) 0.21(0.10) 0.25(0.11) 0.27(0.10) 0.28(0.10)
ffp2 0.11(0.07) 0.13(0.06) 0.15(0.07) 0.16(0.06) 0.16(0.07)
ffp3 0.10(0.07) 0.10(0.05) 0.10(0.05) 0.11(0.04) 0.11(0.05)
rdk5 0.06(0.07) 0.12(0.07) 0.16(0.07) 0.20(0.07) 0.22(0.09)
rdk7 0.05(0.05) 0.14(0.06) 0.23(0.08) 0.36(0.10) 0.43(0.13)
ap 0.05(0.06) 0.15(0.07) 0.22(0.07) 0.31(0.07) 0.36(0.08)
tt 0.01(0.08) 0.05(0.05) 0.09(0.06) 0.12(0.07) 0.13(0.08)print('count-based')
print(f' fp \t 10 20 30 40 50')
for fpn in csims_accum:
means = [np.mean(vs) for vs in csims_accum[fpn].values()]
stds = [np.std(vs) for vs in csims_accum[fpn].values()]
blocks = [f'{x:.2f}({y:.2f})' for x,y in zip(means,stds)]
print(f'{fpn:4s} \t{" ".join(blocks)}')count-based
fp 10 20 30 40 50
mfp0 0.11(0.12) 0.25(0.13) 0.33(0.14) 0.39(0.13) 0.39(0.15)
mfp1 0.06(0.06) 0.14(0.08) 0.19(0.09) 0.24(0.09) 0.24(0.10)
mfp2 0.04(0.05) 0.10(0.06) 0.13(0.06) 0.16(0.06) 0.17(0.08)
mfp3 0.04(0.04) 0.08(0.05) 0.11(0.05) 0.13(0.05) 0.13(0.06)
ffp0 0.39(0.22) 0.45(0.18) 0.48(0.18) 0.55(0.17) 0.55(0.18)
ffp1 0.21(0.13) 0.27(0.12) 0.32(0.13) 0.37(0.12) 0.38(0.13)
ffp2 0.15(0.10) 0.19(0.08) 0.22(0.09) 0.26(0.09) 0.27(0.10)
ffp3 0.14(0.09) 0.15(0.07) 0.17(0.07) 0.20(0.07) 0.20(0.08)
rdk5 0.04(0.06) 0.08(0.08) 0.11(0.08) 0.13(0.08) 0.14(0.09)
rdk7 0.03(0.05) 0.04(0.05) 0.05(0.05) 0.06(0.05) 0.06(0.07)
ap 0.03(0.05) 0.09(0.06) 0.14(0.07) 0.18(0.07) 0.19(0.09)
tt 0.00(0.02) 0.03(0.05) 0.06(0.06) 0.09(0.07) 0.10(0.08)def dfilter(accum,fthresh=0.005,nbins=20):
'''
function to remove extremely small values from the upper values of a data set before doing a histogram
'''
res = []
for v in accum.values():
counts,edges = np.histogram(v,bins=nbins)
tot = np.sum(counts)
thresh = fthresh*tot
edge = edges[-1]
for i,cnt in enumerate(reversed(counts)):
if cnt>thresh:
break
edge = edges[-1*(i+1)]
res.append([x for x in v if x<edge])
return resfpn = 'mfp2'
plt.figure(figsize=(8,10))
plt.subplot(2,1,1)
plt.hist(dfilter(sims_accum[fpn]),bins=20,label=sims_accum[fpn].keys());
plt.legend();
plt.xlabel('similarity (bits)')
plt.title(fpn);
plt.subplot(2,1,2)
plt.hist(dfilter(csims_accum[fpn]),bins=20,label=csims_accum[fpn].keys());
plt.xlabel('similarity (counts)')
plt.legend();
plt.tight_layout()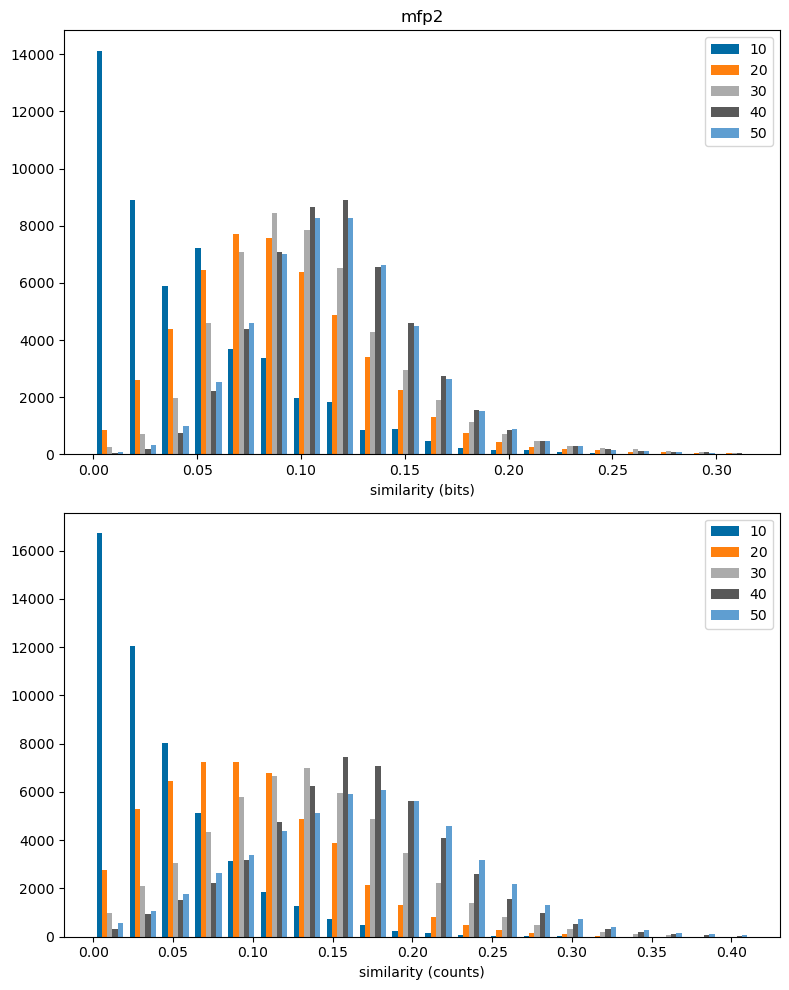
fpn = 'rdk5'
plt.figure(figsize=(8,10))
plt.subplot(2,1,1)
plt.hist(dfilter(sims_accum[fpn]),bins=20,label=sims_accum[fpn].keys());
plt.legend();
plt.xlabel('similarity (bits)')
plt.title(fpn);
plt.subplot(2,1,2)
plt.hist(dfilter(csims_accum[fpn]),bins=20,label=csims_accum[fpn].keys());
plt.xlabel('similarity (counts)')
plt.legend();
plt.tight_layout()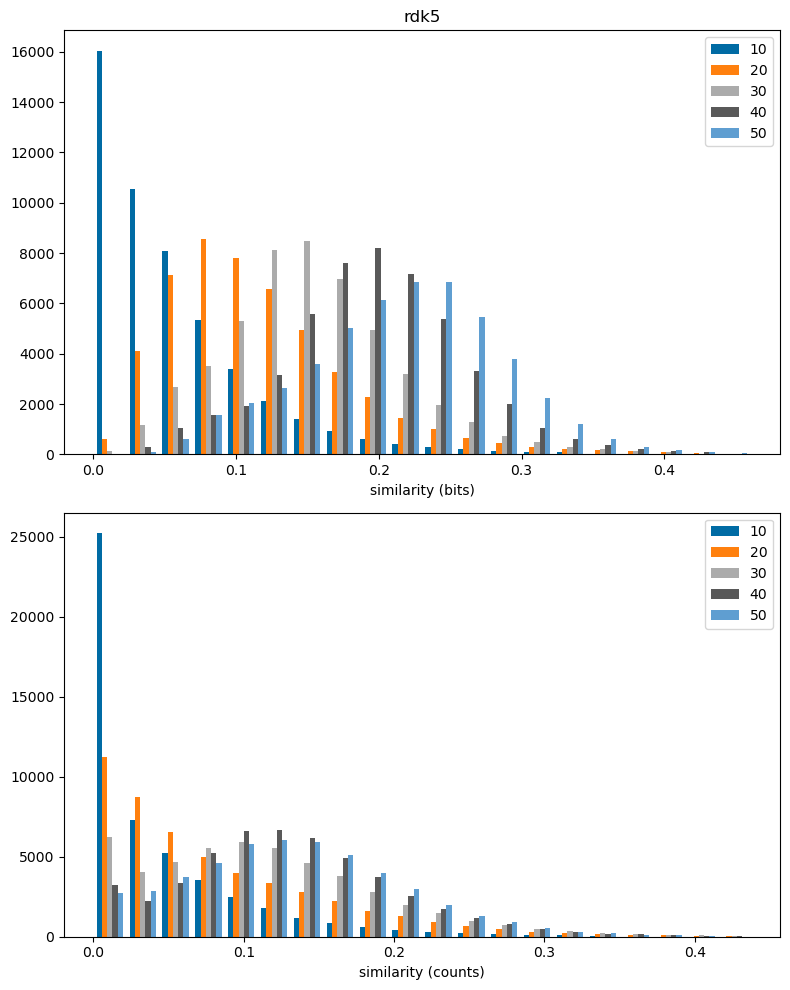
As you’d expect, smaller molecules set way fewer bits:
print('bit-based')
print(f' fp \t 10 20 30 40 50')
for fpn in csims_accum:
means = [np.mean(vs) for vs in bitcounts_accum[fpn].values()]
stds = [np.std(vs) for vs in bitcounts_accum[fpn].values()]
blocks = [f'{x:6.1f}({y:6.1f})' for x,y in zip(means,stds)]
print(f'{fpn:4s} \t{" ".join(blocks)}')bit-based
fp 10 20 30 40 50
mfp0 5.3( 1.6) 8.7( 1.9) 10.0( 2.0) 11.4( 2.1) 11.8( 2.6)
mfp1 11.9( 3.5) 22.1( 4.2) 27.5( 5.0) 34.5( 5.9) 38.1( 8.1)
mfp2 16.4( 5.2) 33.6( 6.4) 44.2( 7.5) 57.9( 8.7) 66.3( 12.2)
mfp3 18.4( 6.5) 43.1( 8.6) 59.3( 10.2) 79.8( 11.2) 93.4( 15.6)
ffp0 2.9( 1.1) 4.5( 1.3) 4.8( 1.2) 5.2( 1.2) 5.3( 1.3)
ffp1 8.8( 2.9) 15.8( 3.8) 18.7( 4.2) 22.8( 4.7) 24.3( 5.8)
ffp2 13.1( 4.4) 26.7( 6.0) 34.1( 7.0) 44.2( 8.1) 49.2( 10.4)
ffp3 15.1( 5.6) 36.2( 8.2) 49.0( 9.7) 65.8( 10.6) 75.8( 14.0)
rdk5 64.7( 37.2) 193.7( 74.1) 289.3( 104.2) 411.9( 129.0) 478.9( 161.4)
rdk7 95.0( 70.0) 444.3( 206.6) 725.5( 281.7) 1039.6( 314.8) 1220.0( 349.5)
ap 26.4( 10.5) 113.6( 30.7) 212.7( 51.9) 372.9( 64.9) 524.2( 92.9)
tt 8.3( 4.6) 25.9( 7.3) 40.7( 9.9) 59.2( 11.4) 74.0( 14.9)print('count-based')
print(f' fp \t 10 20 30 40 50')
for fpn in csims_accum:
means = [np.mean(vs) for vs in cbitcounts_accum[fpn].values()]
stds = [np.std(vs) for vs in cbitcounts_accum[fpn].values()]
blocks = [f'{x:6.1f}({y:6.1f})' for x,y in zip(means,stds)]
print(f'{fpn:4s} \t{" ".join(blocks)}')count-based
fp 10 20 30 40 50
mfp0 5.3( 1.6) 8.8( 1.9) 10.1( 2.0) 11.6( 2.1) 12.1( 2.7)
mfp1 12.1( 3.6) 22.3( 4.3) 27.7( 5.0) 34.9( 6.0) 38.7( 8.3)
mfp2 16.5( 5.3) 33.9( 6.4) 44.7( 7.7) 58.7( 8.9) 67.5( 12.6)
mfp3 18.5( 6.5) 43.6( 8.7) 60.1( 10.5) 81.5( 11.6) 95.7( 16.2)
ffp0 2.9( 1.1) 4.5( 1.3) 4.8( 1.2) 5.2( 1.2) 5.3( 1.3)
ffp1 8.8( 2.9) 15.8( 3.8) 18.7( 4.2) 22.9( 4.8) 24.4( 5.8)
ffp2 13.2( 4.4) 26.9( 6.0) 34.5( 7.1) 44.8( 8.2) 50.1( 10.7)
ffp3 15.1( 5.6) 36.5( 8.3) 49.6( 9.9) 67.2( 10.9) 77.6( 14.4)
rdk5 66.1( 38.8) 205.3( 82.8) 316.0( 124.2) 468.2( 163.8) 560.4( 216.5)
rdk7 98.6( 76.1) 520.7( 284.5) 953.3( 500.9) 1568.9( 709.7) 2064.2( 952.7)
ap 20.9( 9.2) 80.2( 25.2) 140.9( 40.7) 239.3( 61.0) 323.3( 91.1)
tt 6.7( 4.0) 19.5( 6.6) 28.9( 9.1) 40.5( 11.4) 47.6( 14.8)The difference in numbers of bits set between the sparse count-based and bit-based fingerprint is a measure of the number of collisions arising from folding the fingerprint. I’ve done a blog post about this that showed that collisions tend to increase similarity values.
The results above, unsurprisingly, show that collisions are much more prevalent in larger molecules, where more bits are set. This is particularly true for the RDKit fingerprint, which sets a very large number of bits.
Note: by default the bit-based versions of the atom pair and topological torsion fingerprints use count simulation, so features that are present multiple times in a molecule can lead to multiple bits being set in the bit-based fingerprint. This leads to the unusual behavior observed above that there are more bits set in the bit-based fingerprints than the count-based ones, particularly for larger molecules.
fpn = 'rdk7'
plt.figure(figsize=(8,10))
plt.subplot(2,1,2)
plt.hist(dfilter(cbitcounts_accum[fpn]),bins=20,label=cbitcounts_accum[fpn].keys());
lim = plt.xlim()
plt.xlabel('num bits set (counts)')
#plt.xlim(0,0.5);
plt.legend();
plt.subplot(2,1,1)
plt.hist(dfilter(bitcounts_accum[fpn]),bins=20,label=bitcounts_accum[fpn].keys());
plt.xlim(lim[0],lim[1]);
plt.xlabel('num bits set')
plt.legend();
plt.title(fpn)
plt.tight_layout();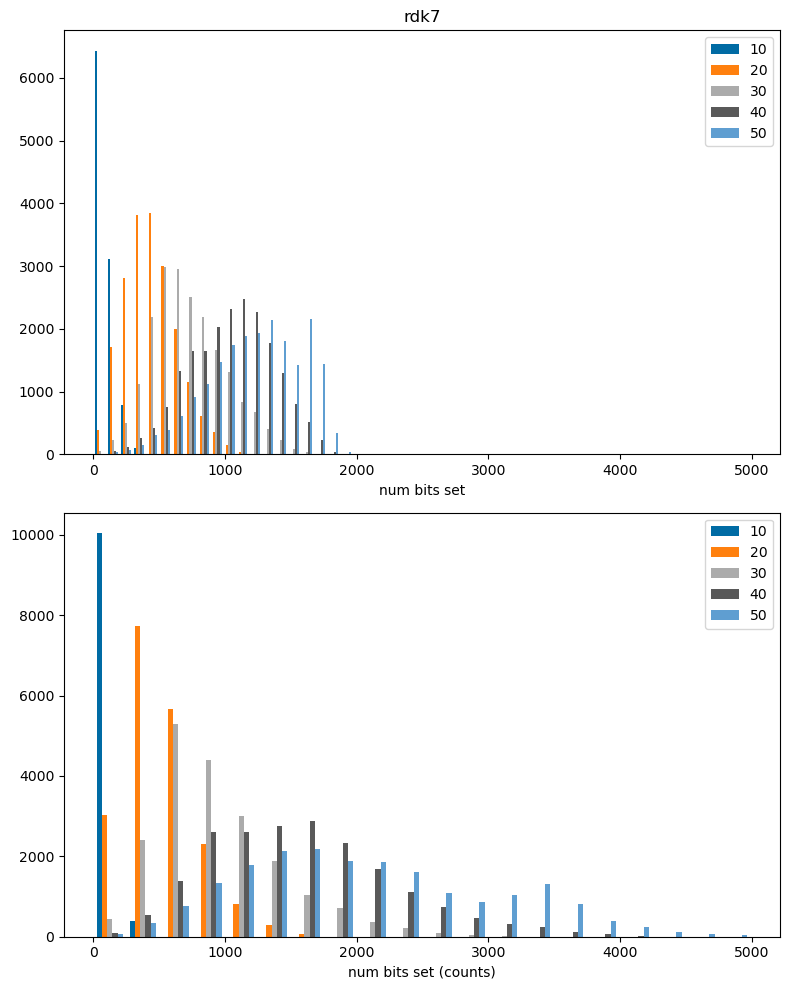
fpn = 'mfp2'
plt.figure(figsize=(8,10))
plt.subplot(2,1,2)
plt.hist(dfilter(cbitcounts_accum[fpn]),bins=20,label=cbitcounts_accum[fpn].keys());
lim = plt.xlim()
plt.xlabel('num bits set (counts)')
#plt.xlim(0,0.5);
plt.legend();
plt.subplot(2,1,1)
plt.hist(dfilter(bitcounts_accum[fpn]),bins=20,label=bitcounts_accum[fpn].keys());
plt.xlim(lim[0],lim[1]);
plt.xlabel('num bits set')
plt.legend();
plt.title(fpn)
plt.tight_layout();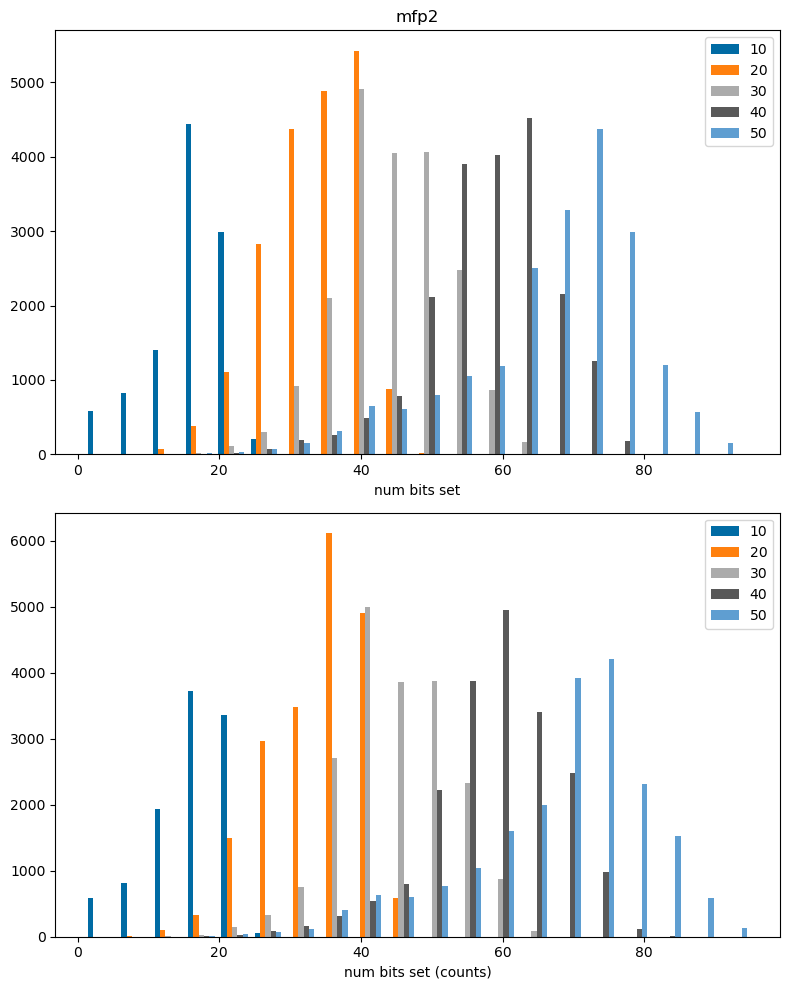
We can directly get stats on the number of collisions:
print('count-based')
print(f' fp \t 10 20 30 40 50')
for fpn in csims_accum:
diffs = [np.array(x)-np.array(y) for x,y in zip(cbitcounts_accum[fpn].values(),bitcounts_accum[fpn].values())]
means = [np.mean(vs) for vs in diffs]
stds = [np.std(vs) for vs in diffs]
blocks = [f'{x:6.1f}({y:6.1f})' for x,y in zip(means,stds)]
print(f'{fpn:4s} \t{" ".join(blocks)}')count-based
fp 10 20 30 40 50
mfp0 0.1( 0.3) 0.2( 0.4) 0.1( 0.3) 0.2( 0.4) 0.3( 0.5)
mfp1 0.1( 0.3) 0.2( 0.4) 0.2( 0.5) 0.4( 0.6) 0.6( 0.7)
mfp2 0.1( 0.4) 0.3( 0.6) 0.5( 0.7) 0.9( 0.9) 1.3( 1.1)
mfp3 0.2( 0.4) 0.5( 0.7) 0.9( 1.0) 1.6( 1.3) 2.3( 1.6)
ffp0 0.0( 0.0) 0.0( 0.0) 0.0( 0.0) 0.0( 0.0) 0.0( 0.0)
ffp1 0.0( 0.2) 0.0( 0.2) 0.0( 0.2) 0.1( 0.2) 0.1( 0.3)
ffp2 0.1( 0.2) 0.2( 0.4) 0.3( 0.6) 0.7( 0.7) 0.9( 0.9)
ffp3 0.1( 0.3) 0.3( 0.6) 0.7( 0.8) 1.3( 1.1) 1.8( 1.3)
rdk5 1.4( 2.0) 11.6( 9.6) 26.7( 21.1) 56.2( 36.5) 81.5( 57.0)
rdk7 3.6( 7.8) 76.4( 83.1) 227.8( 230.7) 529.3( 410.5) 844.2( 621.1)
ap -5.5( 4.6) -33.4( 13.1) -71.8( 23.5) -133.6( 27.9) -201.0( 38.6)
tt -1.6( 2.1) -6.4( 3.6) -11.8( 5.1) -18.6( 5.8) -26.4( 7.7)The negative values here for the atom pair and topological torsion fingerprints are due to count simulation: multiple bits can be set for each feature in the molecule.