Looking at numbers of collisions and their impact on similarity
Published
January 23, 2023
This is an updated and expanded version of an old post
I looked at the number of collisions in Morgan fingerprints in an earlier post. The topic came up again in discussions about the recent post on Morgan fingerprint stats, which used a much larger data set.
Here I repeat the earlier collision analysis using a dataset of 4 million compounds and look at a number of different fingerprint types – Morgan fingeprints of various radii, RDKit fingerprints, atom pair fingerprints, and topological torsion fingerprints– folded to a set of different sizes – 64, 128, 256, 512, 1K, 2K, 4K, 8K, 16K.
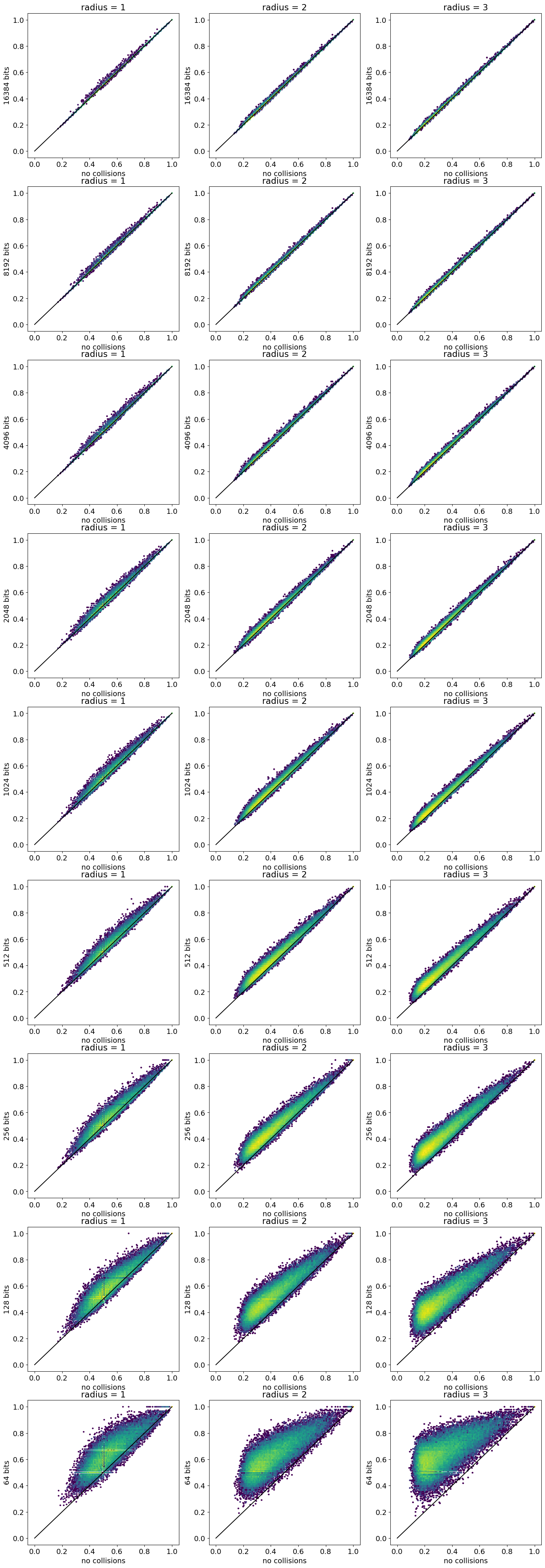
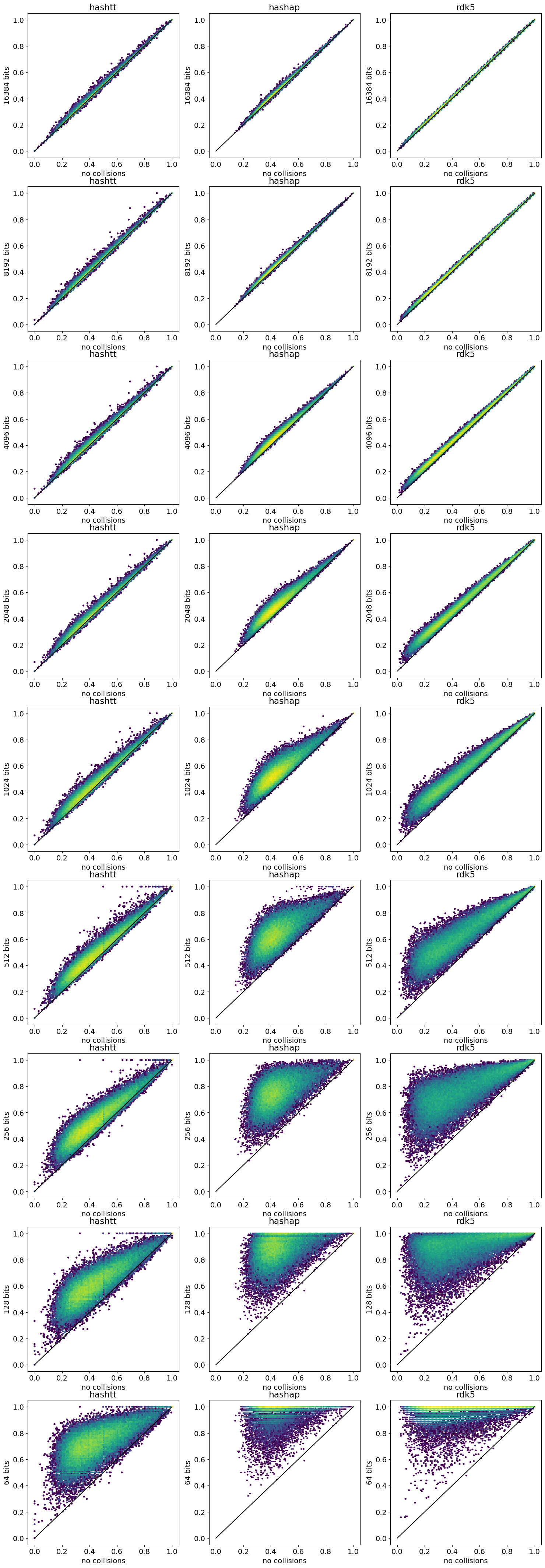
After evaluating the number of collisions, I look at the impact that fingerprint size has on computed similarity values.
TL;DR version: The conclusions match what I observed before, there are a fair number of collisions at fingerprint sizes below 4K. As you would expect, fingerprints with more bits set have more collisions.
Here’s a table with some of the comparisons between Tanimoto similarities calculated with folded fingerprint and those with unfolded fingerprints (the full table is towards the end of the post). In the table d refers to the difference between similarities calculated with the folded and unfolded (=“no” collisions) fingerprint at a particular size. Positive values of d indicate that the similarity with the folded fingerprint is higher than that with the unfolded fingerprint. SpearmanR is the Spearman correlation coefficient between the folded and unfolded similarities.
nBits
fingerprint
SpearmanR
mean(d)
std(d)
90% |d|
16384
mfp1
1.000
0.00023
0.0025
0
16384
mfp2
0.999
0.00085
0.0036
0.0034
16384
mfp3
0.999
0.0014
0.0038
0.0056
16384
rdk5
1.000
0.0054
0.0046
0.012
16384
hashap
0.997
0.0066
0.0072
0.016
16384
hashtt
0.999
0.0024
0.0074
0.011
1024
mfp1
0.989
0.0067
0.016
0.028
1024
mfp2
0.990
0.014
0.016
0.036
1024
mfp3
0.987
0.022
0.017
0.044
1024
rdk5
0.981
0.085
0.049
0.15
1024
hashap
0.874
0.1
0.051
0.17
1024
hashtt
0.983
0.025
0.026
0.061
512
mfp1
0.980
0.013
0.021
0.044
512
mfp2
0.979
0.028
0.023
0.059
512
mfp3
0.972
0.044
0.026
0.078
512
rdk5
0.929
0.16
0.09
0.28
512
hashap
0.702
0.19
0.083
0.3
512
hashtt
0.967
0.046
0.037
0.096
128
mfp1
0.918
0.049
0.043
0.11
128
mfp2
0.897
0.11
0.054
0.18
128
mfp3
0.839
0.17
0.066
0.25
128
rdk5
0.528
0.42
0.2
0.68
128
hashap
0.343
0.42
0.12
0.57
128
hashtt
0.828
0.17
0.085
0.28
64
mfp1
0.832
0.099
0.064
0.18
64
mfp2
0.771
0.2
0.083
0.31
64
mfp3
0.642
0.31
0.1
0.44
64
rdk5
0.235
0.5
0.22
0.77
64
hashap
0.158
0.51
0.13
0.65
64
hashtt
0.672
0.28
0.12
0.43
Down to a fingerprint size of 1024 bits all the fingerprints except hashap have an R of >0.90 and comparatively low deviations (last column). With the very small 128 bit fingerprints only the mfp1 and mfp2 (both of which don’t set many bits) are showing halfway decent performance, and with 64bit fingerprints the deviations are large for all fingerprint types (though the R values for mfp1 and mfp2 are surprisingly high).
There are a number of things worth further exploration here, but those will be other blog posts.
%pylab is deprecated, use %matplotlib inline and import the required libraries.
Populating the interactive namespace from numpy and matplotlib
2022.09.1
Wed Jan 18 13:22:54 2023
/localhome/glandrum/.conda/envs/py310_rdkit/lib/python3.10/site-packages/IPython/core/magics/pylab.py:162: UserWarning: pylab import has clobbered these variables: ['random', 'copy']
`%matplotlib` prevents importing * from pylab and numpy
warn("pylab import has clobbered these variables: %s" % clobbered +
Generating the data
For test data I’ll use the 4 million random compounds from PubChem with <=50 heavy atoms. I constructed the set of compounds by downloading the full pubchem compound set (on 8 Jan, 2023), and picking 10 million random lines using an awk script.
from rdkit import RDLoggerRDLogger.DisableLog('rdApp.*')import copyhistory={} # we will use this to see how quickly the results convergecounts=defaultdict(lambda:defaultdict(int))t1 = time.time()i =0with gzip.open(filen,'rb') as inf:for inl in inf:try: nm,smi = inl.strip().split()except:break m = Chem.MolFromSmiles(smi)if m isNoneor m.GetNumHeavyAtoms()>50:continue i+=1for nm,fpg in gens: fpgen = fpg(1024) # doesn't matter here onbits=len(fpgen.GetSparseFingerprint(m).GetOnBits()) counts[nm][onbits]+=1for l in64,128,256,512,1024,2048,4096,8192,16384: fpnm =f'{nm}-{l}' fpgen = fpg(l) dbits = onbits-fpgen.GetFingerprint(m).GetNumOnBits() counts[fpnm][dbits]+=1ifnot i%50000: t2 = time.time()print(f"Done {i} in {t2-t1:.2f} sec")ifnot i%100000: history[i] = copy.deepcopy(counts)if i>=4000000:break
Done 50000 in 214.60 sec
Done 100000 in 475.92 sec
Done 150000 in 790.69 sec
Done 200000 in 1065.40 sec
Done 250000 in 1350.49 sec
Done 300000 in 1663.03 sec
Done 350000 in 1979.41 sec
Done 400000 in 2289.94 sec
Done 450000 in 2584.58 sec
Done 500000 in 2889.27 sec
Done 550000 in 3156.72 sec
Done 600000 in 3416.83 sec
Done 650000 in 3673.20 sec
Done 700000 in 3930.41 sec
Done 750000 in 4232.50 sec
Done 800000 in 4518.37 sec
Done 850000 in 4788.19 sec
Done 900000 in 5080.44 sec
Done 950000 in 5272.51 sec
Done 1000000 in 5507.97 sec
Done 1050000 in 5831.47 sec
Done 1100000 in 6124.22 sec
Done 1150000 in 6405.13 sec
Done 1200000 in 6699.62 sec
Done 1250000 in 7004.17 sec
Done 1300000 in 7264.67 sec
Done 1350000 in 7525.13 sec
Done 1400000 in 7779.24 sec
Done 1450000 in 8045.30 sec
Done 1500000 in 8314.90 sec
Done 1550000 in 8643.98 sec
Done 1600000 in 8978.91 sec
Done 1650000 in 9292.37 sec
Done 1700000 in 9596.19 sec
Done 1750000 in 9854.10 sec
Done 1800000 in 10134.48 sec
Done 1850000 in 10407.01 sec
Done 1900000 in 10729.17 sec
Done 1950000 in 11005.57 sec
Done 2000000 in 11183.76 sec
Done 2050000 in 11527.20 sec
Done 2100000 in 11831.40 sec
Done 2150000 in 12141.98 sec
Done 2200000 in 12413.20 sec
Done 2250000 in 12708.59 sec
Done 2300000 in 12979.10 sec
Done 2350000 in 13263.71 sec
Done 2400000 in 13504.37 sec
Done 2450000 in 13755.21 sec
Done 2500000 in 13974.78 sec
Done 2550000 in 14282.01 sec
Done 2600000 in 14586.37 sec
Done 2650000 in 14844.31 sec
Done 2700000 in 15153.73 sec
Done 2750000 in 15473.13 sec
Done 2800000 in 15783.14 sec
Done 2850000 in 16093.12 sec
for k,d in history.items(): history[k] =dict(d)pickle.dump(dict(history),gzip.open('../data/fp_collision_counts.history.pkl.gz','wb+'))
with gzip.open('../data/fp_collision_counts.pkl.gz','rb') as inf: counts = pickle.load(inf)with gzip.open('../data/fp_collision_counts.history.pkl.gz','rb') as inf: history = pickle.load(inf)
Quantifying the number of collisions
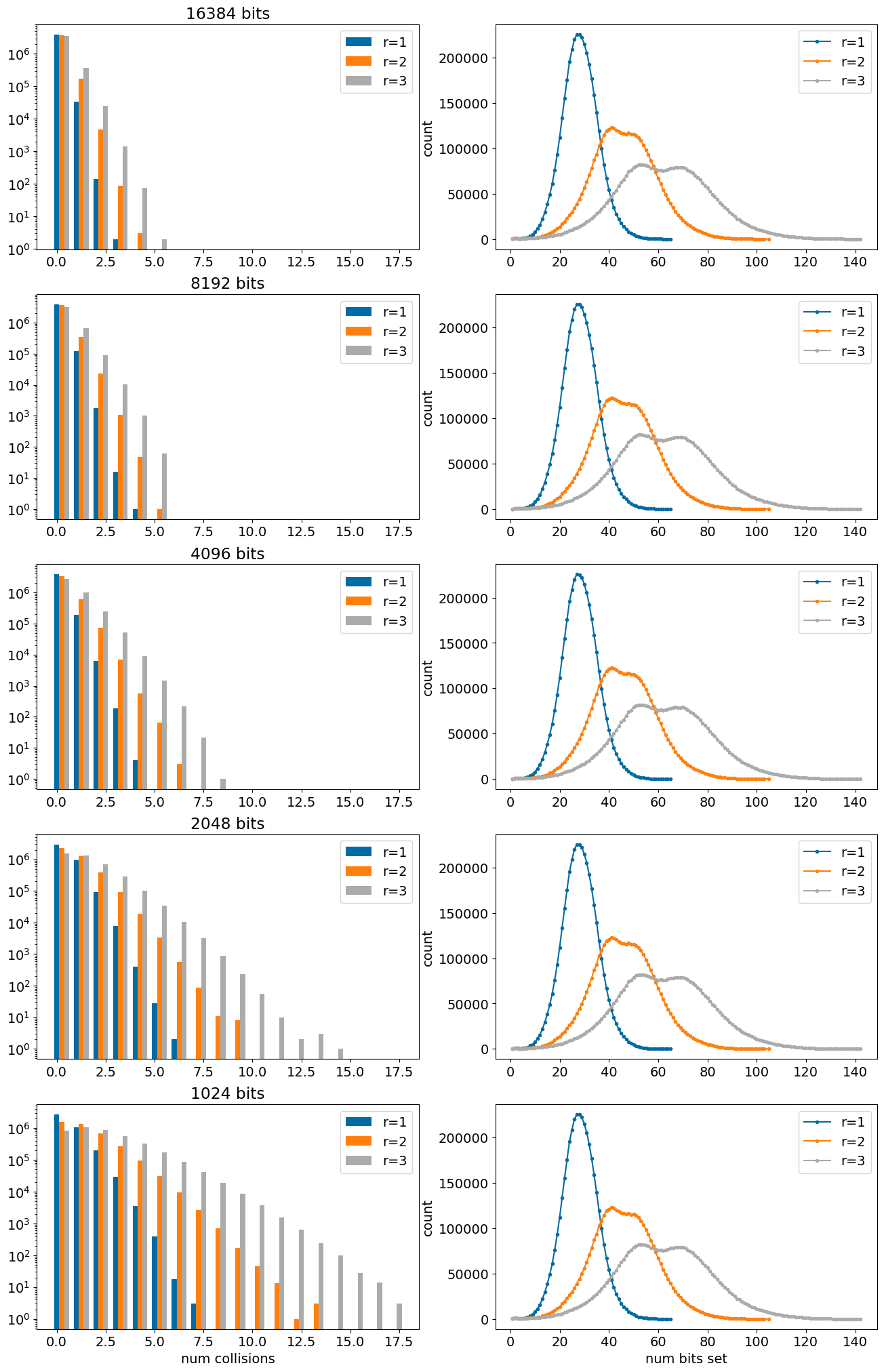
Now plot histograms of the numbers of collisions along with the distributions of the number of bits set in the non-folded FPs
allCounts = (16384, 8192,4096,2048,1024,) #512,256,128,64)figure(figsize=(16,5*len(allCounts)))pidx=1#----------------------------for nbits in allCounts: subplot(len(allCounts),2,pidx) pidx+=1 maxCollisions =max(counts[f'mfp3-{allCounts[-1]}'].keys())+1 d1=np.zeros(maxCollisions,int)for k,v in counts[f'mfp1-{nbits}'].items(): d1[k]=v d2=np.zeros(maxCollisions,int)for k,v in counts[f'mfp2-{nbits}'].items(): d2[k]=v d3=np.zeros(maxCollisions,int)for k,v in counts[f'mfp3-{nbits}'].items(): d3[k]=v barWidth=.25 locs = np.array(range(maxCollisions)) bar(locs,d1,barWidth,label="r=1") bar(locs+barWidth,d2,barWidth,label="r=2") bar(locs+2*barWidth,d3,barWidth,label="r=3")#_=hist((d1,d2,d3),bins=20,log=True,label=("r=1","r=2","r=3")) title('%d bits'%nbits) _=yscale("log") _=legend()if nbits == allCounts[-1]: xlabel('num collisions') subplot(len(allCounts),2,pidx) pidx+=1 itms =list(sorted(counts['mfp1'].items())) plot([x for x,y in itms],[y for x,y in itms],'.-',label="r=1") itms =list(sorted(counts['mfp2'].items())) plot([x for x,y in itms],[y for x,y in itms],'.-',label="r=2") itms =list(sorted(counts['mfp3'].items())) plot([x for x,y in itms],[y for x,y in itms],'.-',label="r=3")if nbits == allCounts[-1]: _=xlabel("num bits set") _=ylabel("count") _=legend()
So, there are definitely some collisions, particularly with radius 3 fingerprints with 1K bits.
The bimodal character of the mfp2 and mfp3 fingerprints is worth following up on: that wasn’t observed in the earlier post, which used a set of compounds from ZINC
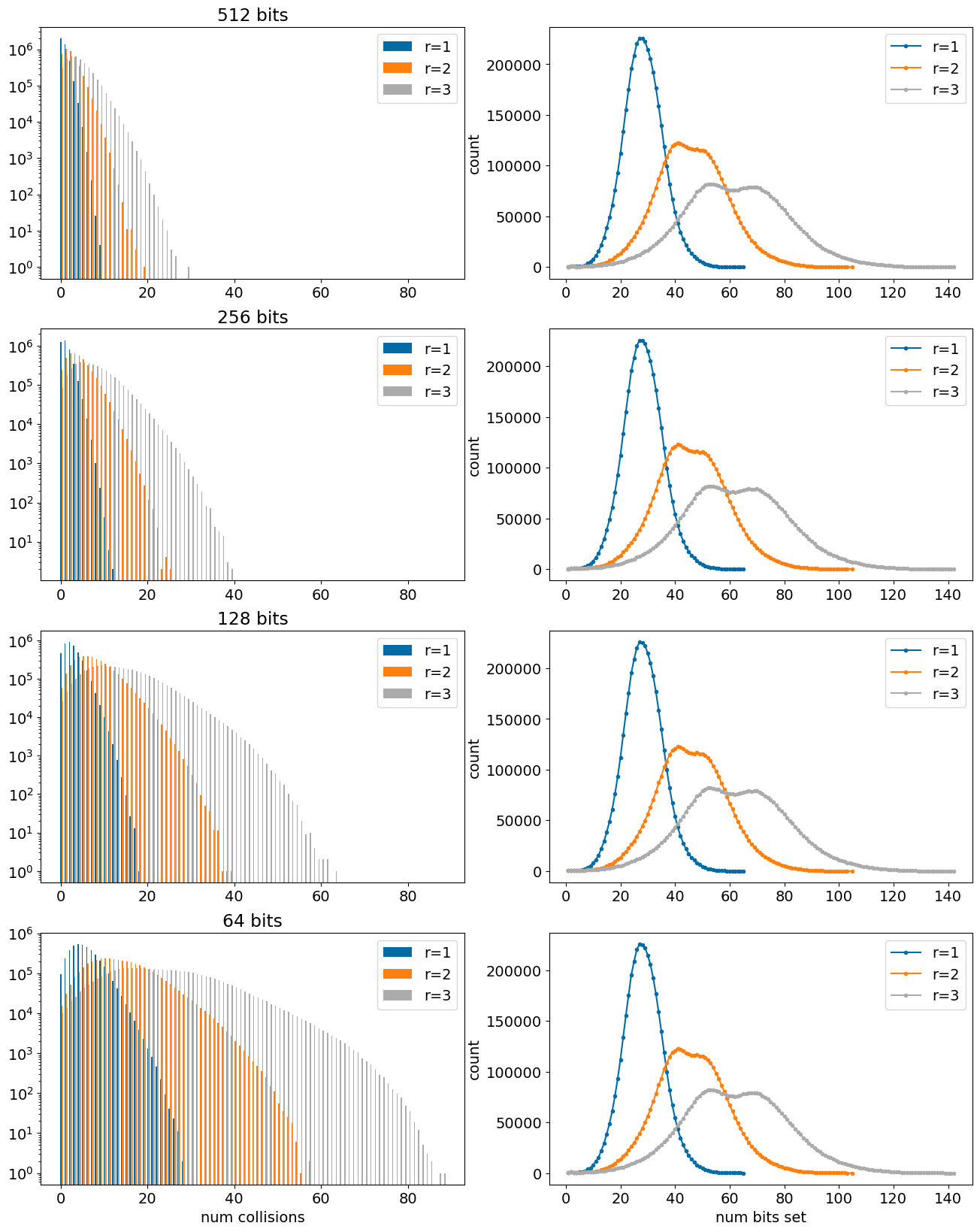
Look the short Morgan fingerprints
allCounts = (512,256,128,64)figure(figsize=(16,5*len(allCounts)))pidx=1#----------------------------for nbits in allCounts: subplot(len(allCounts),2,pidx) pidx+=1 maxCollisions =max(counts[f'mfp3-{allCounts[-1]}'].keys())+1 d1=np.zeros(maxCollisions,int)for k,v in counts[f'mfp1-{nbits}'].items(): d1[k]=v d2=np.zeros(maxCollisions,int)for k,v in counts[f'mfp2-{nbits}'].items(): d2[k]=v d3=np.zeros(maxCollisions,int)for k,v in counts[f'mfp3-{nbits}'].items(): d3[k]=v barWidth=.25 locs = np.array(range(maxCollisions)) bar(locs,d1,barWidth,label="r=1") bar(locs+barWidth,d2,barWidth,label="r=2") bar(locs+2*barWidth,d3,barWidth,label="r=3")#_=hist((d1,d2,d3),bins=20,log=True,label=("r=1","r=2","r=3")) title('%d bits'%nbits) _=yscale("log") _=legend()if nbits == allCounts[-1]: xlabel('num collisions') subplot(len(allCounts),2,pidx) pidx+=1 itms =list(sorted(counts['mfp1'].items())) plot([x for x,y in itms],[y for x,y in itms],'.-',label="r=1") itms =list(sorted(counts['mfp2'].items())) plot([x for x,y in itms],[y for x,y in itms],'.-',label="r=2") itms =list(sorted(counts['mfp3'].items())) plot([x for x,y in itms],[y for x,y in itms],'.-',label="r=3")if nbits == allCounts[-1]: _=xlabel("num bits set") _=ylabel("count") _=legend()
Look at the other fingerprint types. We’ll do this a little differently because of the scales.
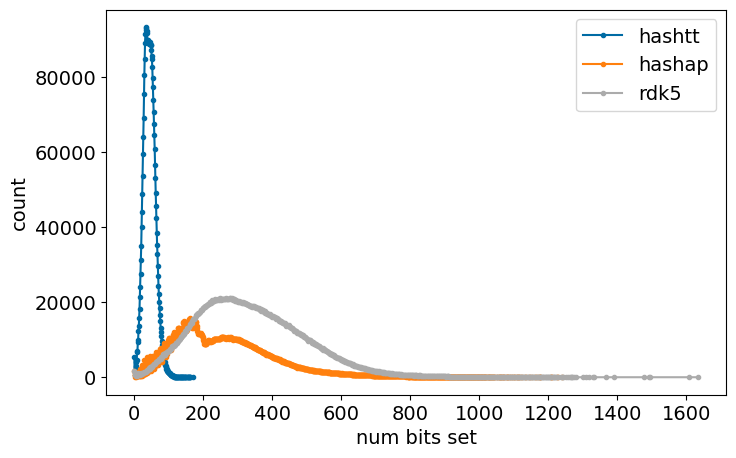
Start with the number of bits set:
figsize(8,5)itms =list(sorted(counts['hashtt'].items()))plot([x for x,y in itms],[y for x,y in itms],'.-',label="hashtt")itms =list(sorted(counts['hashap'].items()))plot([x for x,y in itms],[y for x,y in itms],'.-',label="hashap")itms =list(sorted(counts['rdk5'].items()))plot([x for x,y in itms],[y for x,y in itms],'.-',label="rdk5")if nbits == allCounts[-1]: _=xlabel("num bits set")_=ylabel("count")_=legend()
Both the hashap and hadhtt distributions show more than one peak. Another thing to follow up on…
The topological torsion FPs don’t have a huge number of collisions, but both atom pair and RDKit fingerprints really do have collisions, as one would expect given the number of set bits.
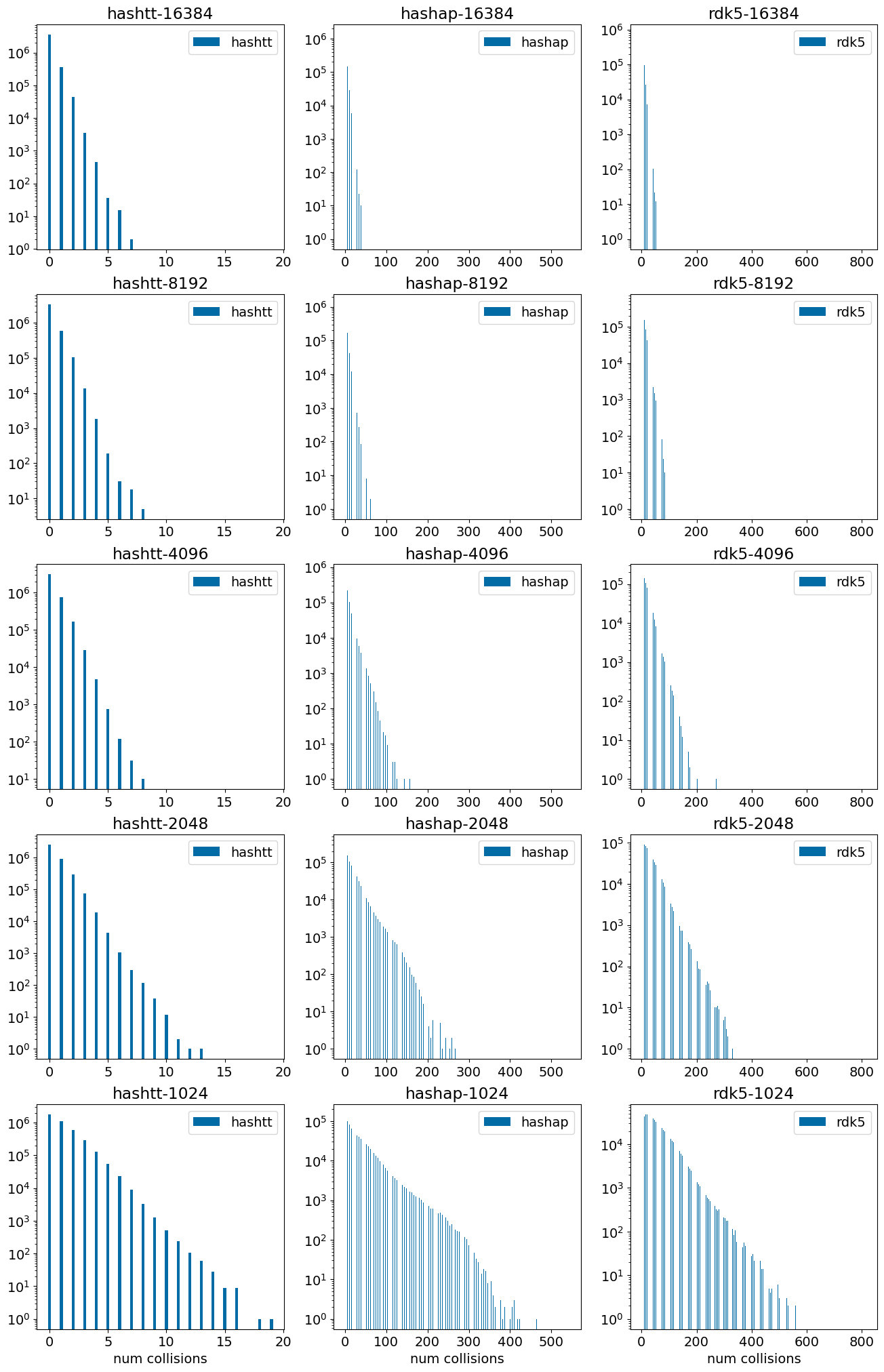
Look at the percentage of compounds with <= a particular number of collisions
bcounts = (64,128,256,512,1024,2048,4096,8192,16384)ccounts =list(range(11))row = ('length','fingerprint',)+tuple(str(x) for x in ccounts)divider = ['-'*len(k) for k in row]print('| '+' | '.join(row)+' |')print('| '+' | '.join(divider)+' |')for bc inreversed(bcounts):for nm,fpg in gens: row = [str(bc),nm] fpn =f'{nm}-{bc}' nmols = np.sum(np.fromiter((x for x in counts[fpn].values()),int)) accum =0for ccount in ccounts: accum += counts[fpn].get(ccount,0) row.append(f'{accum/nmols:.3f}')print('| '+' | '.join(row)+' |')
Notice that the high-density fingerprints - rdk5 and hashap - have collisions for the majority of the compounds even with a 16K fingerprint.
Impact on similarity
Now that we have a sense of how many collisions there are, lets look at the impact those collisions have on molecular similarity.
As a data set we’ll use a set of 50000 pairs of ChEMBL30 molecules with a similarity of at least 0.55 using a count-based morgan fingerprint with radius 1 (MFP1). The jupyter notebook used to generate this data can be found here.
pairs = []for l in gzip.open('../data/chembl30_50K.mfp1.pairs.txt.gz','rt'): l = l.split('\t') pairs.append([Chem.MolFromSmiles(l[1]),Chem.MolFromSmiles(l[3])])
sims = defaultdict(list)for nm,fpgen in gens:print(f'Doing {nm}') fpg = fpgen(1024) # size is irrelevant herefor m1,m2 in pairs: fp1 = fpg.GetSparseFingerprint(m1) fp2 = fpg.GetSparseFingerprint(m2) sims[nm].append(DataStructs.TanimotoSimilarity(fp1,fp2))for l in64,128,256,512,1024,2048,4096,8192,16384: fpn =f'{nm}-{l}' fpg = fpgen(l)for m1,m2 in pairs: fp1 = fpg.GetFingerprint(m1) fp2 = fpg.GetFingerprint(m2) sims[fpn].append(DataStructs.TanimotoSimilarity(fp1,fp2))