Fingerprint similarity thresholds for database searches
Updated 08.06.2021 after I expanded the set of “related compounds”. The source of the previous version of the post is available in github
Prologue
If you’re interested in this topic and have questions, notice mistakes in my analysis, or have suggestions or ideas for improving this (particularly when it comes to the sets of “related compounds” I use), please either send me email or leave a comment.
Intro / Results
One of the RDKit blog posts I refer back to the most is the one where I tried to establish the Tanimoto similarity value which constitutes a “noise level” for each of the fingerprints the RDKit supports by looking at the distributions of similarities between randomly chosen molecules. I periodically update the post just in case the threshold values change with RDKit versions. Here’s the most recent version of the post and the associated jupyter notebook. I find it really useful to be able to say things like “The 95% noise level for Tanimoto similarity calculated with the the bit-based version of the RDKit’s MFP2 is 0.27.” Based on this I know that when doing similarity searches the threshold for MFP2 shouldn’t be set below 0.27 (I normally say 0.3) in most cases. But that analysis doesn’t tell me what I should set the threshold to.
Of course the answer to that question is “it depends”. Let’s assume that the database you’re searching contains a certain number of compounds which would actually be interesting for you and a much larger number of compounds which are not interesting (at least not for the search you’re currently running). And let’s further assume that the similarities between those interesting compounds and your query is generally above the noise level for the fingerprint you’re using. Any similarity search is going to return a mix of both interesting and non-interesting compounds and the proportions in that mix are generally going to be determined by the similarity threshould you use. Setting the similarity threshold high tends to give a larger proportion of interesting compounds at the cost of missing interesting compounds while a lower threshold will return more of the interesting compounds but a higher fraction of uninteresting compounds.
Basically how bad your FOMO is will determine how many results you need to look through.
This isn’t a big deal if you’re searching a small database and or if you’re going to be post-processing the results using some other computational tool, but if the idea is that you’re going to actually be looking at the results of the similarity search, then result sets with 10K or more rows are going to require a lot of patience.
This post is an attempt to come up with recommendations for reasonable threshold values for the common RDKit fingerprints so that you can make a more informed decision about what to use for a given search.
There’s a more complete description below along with links to the jupyter notebooks with the actual code, but here’s a quick summary of what I did: 1. I started with 1047 groups of related compounds (~66K compounds in all). Each group is a set of 50-100 compounds from a single ChEMBL document. 2. I calculated intra-group similarities within each of those 1047 groups using each of the fingerprint types to determine thresholds for retrieving various fractions of each group. 3. I used a randomly selected subset of 10K of those compounds to do similarity searches on 100K molecules randomly selected from ChEMBL in order to determine what fraction of the database would be retrieved for various similarity thresholds.
Here are what the results look like for bit-based MFP2:| 0.95 of related compounds | 0.9 of related compounds | 0.8 of related compounds | 0.5 of related compounds | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Fingerprint | 0.95 noise level | threshold | db fraction / count per million | threshold | db fraction / count per million | threshold | db fraction / count per million | threshold | db fraction / count per million |
| Morgan2 (bits) | 0.27 | 0.4 | 0.00019 / 190 | 0.4 | 0.00019 / 190 | 0.45 | 0.00012 / 115 | 0.55 | 2.5e-05 / 25 |
The 0.95 noise level (from the previous analysis) for this FP is 0.27. If I want to retrieve 95% of the related compounds I need to set the similarity threshold to 0.4. With this threshold I would retrieve ~190 compounds per million compounds in the database (0.4% of the database). Similarly, if I were willing to live with finding 50% of the related actives I could set the search threshold to 0.55, in which case I’d only retrieve ~25 rows per million compounds in the database.
I find this is a useful way of thinking about the thresholds: it makes the balance between recall (number of interesting compounds retrieved) and the overall result set size visible. For example, for the MFP2 results shown above, if I’m willing to live with retrieving about 90% of the interesting compounds instead of 95% I would only have to look through about 1/8th of the results from the database.
With that explained, here’s the full results table:| 0.95 of related compounds | 0.9 of related compounds | 0.8 of related compounds | 0.5 of related compounds | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Fingerprint | 0.95 noise level | threshold | db fraction / count per million | threshold | db fraction / count per million | threshold | db fraction / count per million | threshold | db fraction / count per million |
| MACCS | 0.57 | 0.65 | 0.016 / 15820 | 0.65 | 0.016 / 15820 | 0.7 | 0.0019 / 1880 | 0.8 | 8e-05 / 80 |
| Morgan0 (counts) | 0.57 | 0.6 | 0.017 / 16990 | 0.6 | 0.017 / 16990 | 0.65 | 0.009 / 9040 | 0.75 | 0.00057 / 565 |
| Morgan1 (counts) | 0.36 | 0.5 | 0.0003 / 300 | 0.5 | 0.0003 / 300 | 0.55 | 0.00017 / 170 | 0.65 | 2.5e-05 / 25 |
| Morgan2 (counts) | 0.25 | 0.4 | 0.00014 / 140 | 0.4 | 0.00014 / 140 | 0.45 | 8.5e-05 / 84 | 0.55 | 2e-05 / 20 |
| Morgan3 (counts) | 0.20 | 0.3 | 0.00026 / 260 | 0.35 | 0.00015 / 154 | 0.35 | 0.00015 / 154 | 0.45 | 3.5e-05 / 35 |
| Morgan0 (bits) | 0.57 | 0.6 | 0.019 / 18550 | 0.6 | 0.019 / 18550 | 0.65 | 0.0099 / 9880 | 0.75 | 0.00063 / 629 |
| Morgan1 (bits) | 0.37 | 0.5 | 0.00036 / 360 | 0.5 | 0.00036 / 360 | 0.55 | 0.0002 / 200 | 0.65 | 2.5e-05 / 25 |
| Morgan2 (bits) | 0.27 | 0.4 | 0.00019 / 190 | 0.4 | 0.00019 / 190 | 0.45 | 0.00012 / 115 | 0.55 | 2.5e-05 / 25 |
| Morgan3 (bits) | 0.22 | 0.3 | 0.00057 / 570 | 0.35 | 0.00031 / 309 | 0.4 | 5e-05 / 50 | 0.5 | 2e-05 / 20 |
| FeatMorgan0 (counts) | 0.74 | 0.65 | 0.17 / 165672 | 0.7 | 0.073 / 72975 | 0.7 | 0.073 / 72975 | 0.8 | 0.0086 / 8620 |
| FeatMorgan1 (counts) | 0.51 | 0.55 | 0.021 / 21000 | 0.6 | 0.0024 / 2360 | 0.65 | 0.0012 / 1235 | 0.7 | 0.00011 / 110 |
| FeatMorgan2 (counts) | 0.36 | 0.45 | 0.0038 / 3782 | 0.5 | 0.00023 / 230 | 0.55 | 0.00014 / 135 | 0.65 | 2.5e-05 / 25 |
| FeatMorgan3 (counts) | 0.28 | 0.4 | 0.00022 / 220 | 0.4 | 0.00022 / 220 | 0.45 | 0.00013 / 130 | 0.55 | 3e-05 / 30 |
| FeatMorgan0 (bits) | 0.74 | 0.65 | 0.17 / 165672 | 0.7 | 0.073 / 72975 | 0.7 | 0.073 / 72975 | 0.8 | 0.0086 / 8620 |
| FeatMorgan1 (bits) | 0.51 | 0.55 | 0.023 / 22962 | 0.6 | 0.0027 / 2660 | 0.65 | 0.0014 / 1390 | 0.7 | 0.00012 / 120 |
| FeatMorgan2 (bits) | 0.38 | 0.45 | 0.006 / 6007 | 0.5 | 0.00031 / 310 | 0.55 | 0.00018 / 175 | 0.65 | 2.5e-05 / 25 |
| FeatMorgan3 (bits) | 0.30 | 0.4 | 0.00037 / 370 | 0.45 | 0.00021 / 210 | 0.45 | 0.00021 / 210 | 0.55 | 3.5e-05 / 35 |
| RDKit 4 (bits) | 0.33 | 0.5 | 0.00069 / 690 | 0.55 | 0.0004 / 400 | 0.6 | 0.00011 / 110 | 0.7 | 4e-05 / 40 |
| RDKit 5 (bits) | 0.29 | 0.5 | 0.00025 / 250 | 0.55 | 0.00016 / 155 | 0.6 | 6e-05 / 60 | 0.7 | 3e-05 / 30 |
| RDKit 6 (bits) | 0.31 | 0.5 | 0.00021 / 210 | 0.55 | 0.00014 / 135 | 0.6 | 6e-05 / 60 | 0.7 | 3e-05 / 30 |
| RDKit 7 (bits) | 0.43 | 0.55 | 0.00051 / 510 | 0.6 | 8e-05 / 80 | 0.6 | 8e-05 / 80 | 0.7 | 3e-05 / 30 |
| linear RDKit 4 (bits) | 0.35 | 0.5 | 0.0015 / 1470 | 0.55 | 0.00083 / 830 | 0.6 | 0.00019 / 190 | 0.7 | 5e-05 / 50 |
| linear RDKit 5 (bits) | 0.31 | 0.5 | 0.00046 / 455 | 0.55 | 0.00027 / 272 | 0.6 | 9e-05 / 90 | 0.7 | 3e-05 / 30 |
| linear RDKit 6 (bits) | 0.28 | 0.5 | 0.00022 / 220 | 0.5 | 0.00022 / 220 | 0.55 | 0.00014 / 140 | 0.7 | 3e-05 / 30 |
| linear RDKit 7 (bits) | 0.26 | 0.45 | 0.00053 / 535 | 0.5 | 0.00013 / 130 | 0.55 | 9e-05 / 90 | 0.65 | 3.5e-05 / 35 |
| Atom Pairs (counts) | 0.27 | 0.35 | 0.0037 / 3724 | 0.35 | 0.0037 / 3724 | 0.4 | 0.00016 / 160 | 0.5 | 3e-05 / 30 |
| Topological Torsions (counts) | 0.19 | 0.35 | 0.00049 / 489 | 0.4 | 0.00011 / 110 | 0.45 | 7.5e-05 / 75 | 0.55 | 2.5e-05 / 25 |
| Atom Pairs (bits) | 0.36 | 0.4 | 0.01 / 10380 | 0.45 | 0.0053 / 5250 | 0.5 | 0.00012 / 120 | 0.55 | 7e-05 / 70 |
| Topological Torsions (bits) | 0.22 | 0.4 | 0.00016 / 160 | 0.4 | 0.00016 / 160 | 0.45 | 0.00011 / 105 | 0.55 | 3.5e-05 / 35 |
| Avalon 512 (bits) | 0.51 | 0.65 | 0.0004 / 400 | 0.65 | 0.0004 / 400 | 0.7 | 8e-05 / 80 | 0.8 | 2e-05 / 20 |
| Avalon 1024 (bits) | 0.37 | 0.55 | 0.00075 / 750 | 0.6 | 0.00014 / 140 | 0.65 | 9e-05 / 90 | 0.75 | 2.5e-05 / 25 |
| Avalon 512 (counts) | 0.42 | 0.55 | 0.0028 / 2785 | 0.6 | 0.00028 / 280 | 0.65 | 0.00016 / 160 | 0.75 | 2.5e-05 / 25 |
| Avalon 1024 (counts) | 0.38 | 0.55 | 0.0012 / 1192 | 0.6 | 0.00017 / 170 | 0.6 | 0.00017 / 170 | 0.7 | 4e-05 / 40 |
The threshold values are rounded to the nearest 0.05.
Method
I won’t get into heavy detail here, the actual notebooks are linked below.
Similarity between random molecules
The workflow and dataset for this is described in a blog post. The very quick summary is that I generated statistics for the similarity distribution of 25K random pairs of reasonable sized (MW<600) molecules exported from ChEMBL.
Determining background retrieval rates
In order to get a sense of how many compounds would be retrieved from a database when using the related compounds, I randomly picked 100K molecules from ChEMBL28 to use as a background. I wanted a representative sample, so I didn’t apply MW filters when doing this selection.
I then queried the background compounds with each molecule in a random subset of the 66K members of the “related compounds” set, counted the number of results each returned for each fingerprint/similarity threshold combination, and did statistics based on those results.
Summarizing the data
Here’s an example of a graphical summary of the results presented in the final notebook listed below:
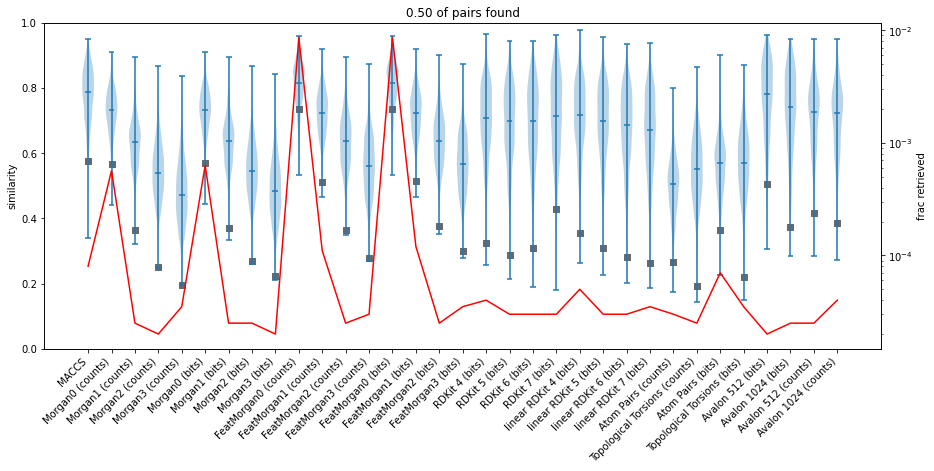
The violin plots show the distribution of similarity values required to match 50% of the related compound pairs for each of the fingerprints. The dark gray boxes show the noise level for the fingerprints. The red line shows the median fraction of the 100K ChEMBL compounds retrieved when using the median value from the violin plots as a similarity threshold.
The notebooks
Here are the github links for the notebooks I used: - Similarity between random molecules (this is the previous analysis): https://github.com/greglandrum/rdkit_blog/blob/master/notebooks/Fingerprint%20Thresholds.ipynb - Finding scaffolds for ChEMBL documents with Ki values (also a previous analysis): https://github.com/greglandrum/rdkit_blog/blob/master/notebooks/Finding%20Scaffolds%20Revisited%20again.ipynb - Similarity distributions for related compounds: https://github.com/greglandrum/rdkit_blog/blob/master/notebooks/Fingerprint%20Thresholds%20Scaffolds.ipynb Note that this is a new one and I’m still working on cleaning it up and adding more text/explanation - Fraction of the database retrieved when searching (this one also has the calculation of the summary results presented here): https://github.com/greglandrum/rdkit_blog/blob/master/notebooks/Fingerprint%20Thresholds%20Database%20Fraction.ipynb Note that this is a new one and I’m still working on cleaning it up and adding more text/explanation